InnoDB架构及物理存储
InnoDBis a general-purpose storage engine that balances high reliability and high performance.
InnoDB作为MySQL默认引擎,深入了解InnoDB有助于加深对于数据库系统的理解,下面首先从InnoDB的架构出发,介绍InnoDB的组成以及表数据的物理存储方式,其他例如事务、并发控制等相关内容在本文中不展开。
InnoDB架构
这部分内容是对MySQL 8.0 Reference Manual学习自我总结
InnoDB分为内存结构和磁盘结构两部分,其中内存结构主要为了减少磁盘访问,从而让提升访问性能,磁盘结构部分负责InnoDB中数据的实际物理存储。

In-Memory Structrues
内存结构中的主要结构有四个:
Buffer Pool:缓存历史访问数据和索引,用来减少磁盘访问Change Buffer:缓存对非Buffer pool中数据的修改,当页面加载到Buffer pool中时,会将修改合并到对应页面上Adaptive hash index(AHI):自适应哈希索引,对于某些访问”频繁“数据的数据,在内存中建立索引到数据页的直接映射- ”频繁“定义为:数据页寻路时间长,或者多个SQL命中相同页面
- 与
Buffer Pool共用空间
Log Buffer:缓存redo log数据,默认大小为16MB,周期性刷出到磁盘中
Buffer Pool采用LRU机制进行缓存数据页的汰换,将内存空间划分为了New Sublist(5/8)和Old Sublist(3/8),从上到下数据页的新旧程度变旧,页面汰换策略如下:
Midpoint Insertion新页面插入策略,即每次插入新页面时,插入到New Sublist尾部,Old Sublist头部。为了解决一次查询的结果只使用一次,但是涉及到大量数据页导致缓存大量刷出的情况- 当访问
Buffer pool中的旧页时,会将旧页面移动到New Sublist的头节点 - 当缓冲区内存够空间不足时,会从
Old Sublist尾部踢出页面

Change Buffer 是为了减少磁盘访问的另一手段,当修改数据不在内存中时,将修改缓存在该缓存中,当下次需要访问修改涉及页面是,将数据页读入内存后执行merge操作
- 周期性将缓存中的修改写入到对应磁盘中,将大量随机访问转化成了成批次的集中访问,一定程度降低修改的成本。
- 当修改操作涉及到读取数据页时,不会写入
Change buffer,例如delete***id = 1,因为执行修改操作前数据页面一定已经加载到内存中。 - 系统表空间中存有
Change Buffer的备份
On-Disk Structures
磁盘中的结构主要包括各种表空间和其他文件
- 表空间:数据的逻辑存储方式,包括系统表空间、用户表空间、临时表空间等等
- 其他文件:二次写文件、redo log文件等
InnoDB中表的物理存储概念从大到小为:表空间->段->区->页
- 表空间(Table space):物理存储中的一个表。
- 段(Segement):表的逻辑组成部分,一个表一般包括数据段、索引段等,一个段以区为单位进行空间分配。
- 区(Extent):64个数据页组成一个区,由于数据页过小,以页进行分配和访问较为离散,成本较高,因此多个页构建区的概念,方便连续存储和访问。
- 页(Page):磁盘管理的最小数据单位,一个页包含多个数据项,页大小一般为16KB。
根据上述存储逻辑,一个表空间的空间分配逻辑可以如下理解:
- 创建表时首先默认创建两个段,叶子节点段和非叶子节点段
- 插入数据时,首先在碎片区以页为单位分配存储空间,当某个段占用32个碎片区页面后,再以完整的区为单位,分配存储空间
- 此时的段概念等价于:区+碎片区页
二次写文件对应InnoDB的二次写机制(double write):
- double write:将脏页真正写入对应磁盘页之前,首先分两次每次写入1MB到
Double Write Buffer也就是二次写文件中,完成该操作后再写入真正的磁盘页中。 - 主要为了解决页面写入中途崩溃,导致页面受损无法恢复即页断裂(partial write)问题
- 为什么不能用redo log解决?本质上是由于不同层IO的粒度不同,其中DB block (8-16K)> OS block (4K)>= IO block > 磁盘 sector(512byte),redo log针对的整个页面的状态变更,此时页面的一部分损坏,redo log无法处理该程度的损坏
redo log file在后续事务学习中再进行总结
物理存储格式
上文中表存储表空间、段、区并不是真正的物理存储结构,而是一个逻辑上的表和空间分配的单位,InnoDB实际上的物理存储分为页格式和行格式,其中页中存储行,下面分别进行总结
页格式
一个InnoDB数据页被划分为7部分:
- File Header(38 Bytes):文件头,包括页号、到其他页链接、页面类型等的页面信息
- Page Header(56 Bytes):页头,记录页面内数据信息,例如最新插入位置、事务ID等
- Infimum + Supremum Records(26 Bytes):最小记录和最大记录 两个虚拟的行记录
- User Records :存储数据行
- Free Space:空闲空间
- Page Directory:页中的”槽”的相对位置,InnoDB对数据行进行均匀划分称为”槽“
- File Trailer(8 Bytes):文件尾,和头各有一个校验和和LSN,验证页面的数据完整性

每个表对应一个表空间,对应data_dir中的一个.ibd文件

行格式
表中的每一行对应数据页中User Records区域中的一个数据行,InnoDB中有四种行格式,分别为
- Redundant:最早的默认行格式
- Compact:对Redundant行格式的概念,当前版本的默认行格式
- Compressed和Dynamic:InnoDB1.0.x引入的两种行格式,合称为Barracuda,并将前两种格式合称为Antelope
- 3两种格式与1,2格式的不同点在于其对于行溢出的处理。1,2格式在数据大于768byte时,存储前768byte的数据+指针,其余溢出数据存储到
off page中;3两种格式对于行溢出只存储指针不存储数据 - Compressed和Dynamic的区别在于前者可以使用zlib库对行数据进行压缩
- 3两种格式与1,2格式的不同点在于其对于行溢出的处理。1,2格式在数据大于768byte时,存储前768byte的数据+指针,其余溢出数据存储到
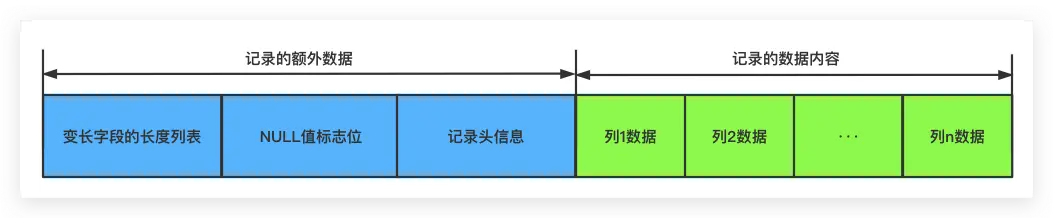
Compact格式如下图所示(两张格式示意图均来自知乎博客)
- 变长字段长度列表:按照反向字段顺序放置,当字段长度不超过255byte时,使用1个字节表示;当字段长度大于255byte时,使用2个字节表示
- Null值列表:1bite,01表示对应字段为空,不包括定义非空的字段
- 记录头信息:包括如delete_flag、record_type、next_record等记录信息,同一个页中的记录通过next_record连接称为单向链表
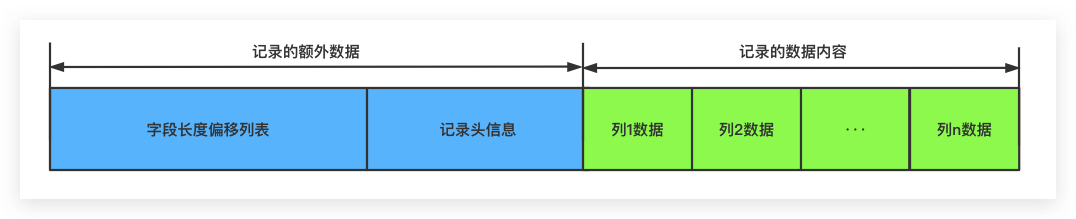
Redundant格式与Compact格式基本相同
- 字段长度偏移列表:记录每个字段的偏移量(反向字段顺序)
- 没有null值列表,在便宜列表中相邻偏移量差为0,代表null